
PostgreSQL基本知识
把存货扔一点上来...水水更健康
这里会介绍一些pg内部的结构,没有什么具体的逻辑,属于是讲到哪是哪。
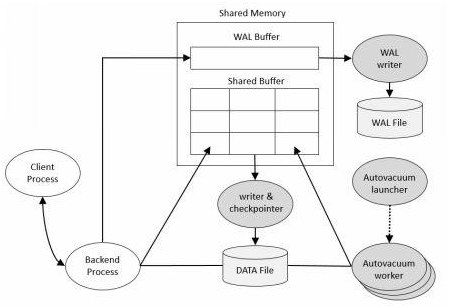
整体架构
文件管理
VFD机制
系统对于单个进程可以打开的文件数量是有一定限制的(通常来说是1024,可以通过ulimit -n查看),但是这个文件数量对于某些场景可能是不够用的,比如扫描,排序等等。因此PostgreSQL使用了叫VFD(Virtual file descriptor)来对打开的文件进行管理。
PG会使用LRU机制来管理当前打开的所有文件,LRU通过一个存放Vfd的数组VfdCache来实现,Vfd是对于实际使用的文件句柄的一层封装,结构如下:
typedef struct vfd
{
int fd; /* current FD, or VFD_CLOSED if none */
unsigned short fdstate; /* bitflags for VFD's state */
ResourceOwner resowner; /* owner, for automatic cleanup */
File nextFree; /* link to next free VFD, if in freelist */
File lruMoreRecently; /* doubly linked recency-of-use list */
File lruLessRecently;
off_t fileSize; /* current size of file (0 if not temporary) */
char *fileName; /* name of file, or NULL for unused VFD */
/* NB: fileName is malloc'd, and must be free'd when closing the VFD */
int fileFlags; /* open(2) flags for (re)opening the file */
mode_t fileMode; /* mode to pass to open(2) */
} Vfd; 其中fileFlags和fileMode, fd记录了打开句柄时的参数,另外fdstate代表的含义如下所示:
/* these are the assigned bits in fdstate below: */
#define FD_DELETE_AT_CLOSE (1 << 0) /* T = delete when closed */
#define FD_CLOSE_AT_EOXACT (1 << 1) /* T = close at eoXact */
#define FD_TEMP_FILE_LIMIT (1 << 2) /* T = respect temp_file_limit */ 对于单个进程来说,VfdCache上维护了两个链表:一个是双向LRU链表,另一个是FreeList链表,nextFree和lruMoreRecently,lruLessRecently就确定了每个记录是否以及被打开。数组的第一个位置不会被使用,用于标志LRU链表和空闲链表的起始。
当进程申请打开一个文件时,首先需要获取一个数组中的位置来存储信息(AllocateVfd),先尝试空闲链表中获取,如果空闲链表为空,则会扩大数组,之后分配得到一个Vfd,如果此时打开的文件数量已经大于max_safe_fds,会从LRU链表中不断关闭文件,直到可以打开新的文件。
磁盘管理器
由于系统对于文件大小也存在限制(通常来说是2G),因此一个表会被分割并存储在多个段文件(segment)中,每个段都通过_MdfdVec的结构体来存储,记录了相应的Vfd位置以及segment number:
typedef struct _MdfdVec
{
File mdfd_vfd; /* fd number in fd.c's pool */
BlockNumber mdfd_segno; /* segment number, from 0 */
} MdfdVec; 每个表通过SMgrRelationData结构体来管理
typedef struct SMgrRelationData
{
/* rnode is the hashtable lookup key, so it must be first! */
RelFileNodeBackend smgr_rnode; /* relation physical identifier */
/* pointer to owning pointer, or NULL if none */
struct SMgrRelationData **smgr_owner;
/*
* These next three fields are not actually used or manipulated by smgr,
* except that they are reset to InvalidBlockNumber upon a cache flush
* event (in particular, upon truncation of the relation). Higher levels
* store cached state here so that it will be reset when truncation
* happens. In all three cases, InvalidBlockNumber means "unknown".
*/
BlockNumber smgr_targblock; /* current insertion target block */
BlockNumber smgr_fsm_nblocks; /* last known size of fsm fork */
BlockNumber smgr_vm_nblocks; /* last known size of vm fork */
/* additional public fields may someday exist here */
/*
* Fields below here are intended to be private to smgr.c and its
* submodules. Do not touch them from elsewhere.
*/
int smgr_which; /* storage manager selector */
/*
* for md.c; per-fork arrays of the number of open segments
* (md_num_open_segs) and the segments themselves (md_seg_fds).
*/
int md_num_open_segs[MAX_FORKNUM + 1]; //记录打开的段数量,和下面一一对应
struct _MdfdVec *md_seg_fds[MAX_FORKNUM + 1]; //是个二维数组(4行N列),定位每个段文件的链表
/* if unowned, list link in list of all unowned SMgrRelations */
dlist_node node;
} SMgrRelationData; 表文件中的segment是逐个打开的,打开的segment会记录在md_seg_fds中,相应的打开数量则是在md_num_open_segs中。
一个表文件会被拆分到多个文件块(称为段文件、文件块、页面块),每个表文件有多个BLCKSZ=8192B大小的文件块组成。pg在内存中开辟了缓冲区用于存储这些文件块,每个缓冲区的大小和文件页面块的大小相同。磁盘上的文件块读入内存后被存放在缓冲区中,称之为页面块或缓冲块。
Hash Table
Hash Table定义在hsearch.h中,对我们来说,暂时先不关心其内部的实现,主要看一下外部的相关接口
- 一个
HTAB的创建是通过hash_create来完成的 - 对应的销毁则是通过
hash_destroy来完成
RelFileNode
typedef struct RelFileNode
{
Oid spcNode; /* tablespace */
Oid dbNode; /* database */
Oid relNode; /* relation */
} RelFileNode;RelFileNode:主要用于定位一个关系表的物理位置。
spcNode用于确定tablespace,tablespace可以通过\db+查看,在initDB后,会默认创建两个tablespace,如下就是查询结果。
List of tablespaces
Name | Owner | Location | Access privileges | Options | Size | Description
------------+----------+----------+-------------------+---------+--------+-------------
pg_default | postgres | | | | 33 MB |
pg_global | postgres | | | | 560 kB | 其中我们默认创建的database都会位于pg_default下,另一个pg_global就是用于存储一些共享信息。
在这篇文章中,推荐将database创建于非默认tablespace中,他提出了三个优点
- logically maintaining the objects on specific directory
- better I/O retention
- Maintenance activities (like to take backup specific volume backup)
而在这篇文章中,观点又与上面相反,大部分情况下,不需要创建额外的tablespace,除了某些例外情况
- 数据分布在多个设备的多个文件系统上(this can be done just as well or better by striping on a lower level. ==What?==)
- 同时拥有不同I/O速度的设备(可以通过调整
seq_page_cost,random_page_cost,effective_io_concurrency来代替) - 限制某些database的大小
dbNode确定了关系所在的database,如果该值为0,则表示这个关系是一个共享的关系,否则,其值对应于pg_database.oid
relNode则表示具体的关系(Name of the on-disk file of this relation),其值对应于pg_class.relfilenode,初始时该值也等于pg_class.oid,但是当该文件被重写时,relNode就会被赋予一个新的值,而pg_class.oid不变

pg_class存放了所有像表的结构,比如索引,序列,试图等等(通过
relkind区分类型)。这个表里还有些好玩的东西,比如reltuples,是对于表中tuple数量的估计,会被执行计划使用到,仅会在VACUUM, ANALYZE 和 CREATE INDEX 时更新
Buffer缓冲池
postgresql对于缓冲区采用静态管理方式,其基本结构如下图所示。
最上层是buffer table layer,是一个哈希表,其内部存储了BufferTag到BufferDesc的映射。BufferTag存储了一个缓存页对应的物理页的信息,记录了relNode,forkNum和blockNo
typedef struct BufferDesc {
BufferTag tag; /* ID of page contained in buffer */
int buf_id; /* buffer's index number (from 0) */
/* state of the tag, containing flags, refcount and usagecount */
pg_atomic_uint32 state;
int wait_backend_pid; /* backend PID of pin-count waiter */
int freeNext; /* link in freelist chain */
LWLock content_lock; /* to lock access to buffer contents */
} BufferDesc; BufferDesc则是和buffer pool中的页面一一对应,其中buf_id就指向了具体的页面位置,同时还会存储一些其他信息,比如用于缓存页替换的freeNext链表,用于记录每个页面当前状态的state等(是否为脏,是否被上锁,pin的数量等等)。
Backend-Private refcount management
为了快速的判断某个buffer是否已经被当前进程pin住,每个进程都会创建一个数组PrivateRefCountArray以及一个哈希表PrivateRefCountHash来记录自己持有的页面。在PrivateRefCountArray查询较快,作为高速通道,大小默认为8,而较慢的哈希表则作为二级缓存。
Share memory
如果要在pg的不同进程内修改或读取同一个变量,就必须要用到共享内存。共享内存是怎么创建的呢?
-
共享内存主要在
CreateSharedMemoryAndSemaphores内进行初始化,这个工作是由postmaster进程来进行 -
计算出需要使用多少大小的共享内存,通过
add_size进行添加 -
使用
ShmemInitStruct进行初始化,比如可以看到checkpointer的共享结构体是在CheckpointerShmemInit内初始化的,缓冲区是在InitBufferPool内进行初始化的
在linux平台下,共享内存是通过mmap来实现的,具体位于PGSharedMemoryCreate内。下面这段代码就是一个简单的例子来实现共享内存,可以先运行看看结果,然后去掉USE_MMAP宏再看看使用malloc的结果。当然要注意,通过这种方法进行的共享只能在调用mmap的进程以及其子进程之间进行,所以pg的共享缓冲区初始化都是在postmaster中进行的
#include <iostream>
#include<sys/mman.h>
#include <signal.h>
#include <setjmp.h>
#include <unistd.h>
#include <sys/time.h>
#include <stdlib.h>
#define USE_MMAP
#ifdef USE_MMAP
void* CreateShareMemory(int size) {
void* ptr = mmap(NULL, size, PROT_READ | PROT_WRITE,
MAP_SHARED|MAP_ANONYMOUS, -1, 0);
return ptr;
}
void FreeShareMemory(void* ptr, int size) {
munmap(ptr, size);
}
#else
void* CreateShareMemory(int size) {
return malloc(size);
}
void FreeShareMemory(void* ptr, int size) {
free(ptr);
}
#endif
struct Test {
bool v1;
int v2;
double v3;
};
void* sharedMemory = NULL;
Test* test;
int main() {
sharedMemory = CreateShareMemory(4096);
test = (Test*)sharedMemory;
test->v1 = false;
test->v2 = 2;
test->v3 = 12.33;
int pid1 = fork();
if (pid1 == 0) {
sleep(1);
std::cout << "in child: " << getpid() << ", parent = " << getppid() << ", test = " << test->v1 << " " << test->v2 << " " << test->v3 << std::endl;
return 0;
}
int pid2 = fork();
if (pid2 == 0) {
std::cout << "in child: " << getpid() << ", parent = " << getppid() << ", test = " << test->v1 << " " << test->v2 << " " << test->v3 << std::endl;
test->v1 = true;
test->v2++;
test->v3 = 33.21;
return 0;
}
sleep(2);
FreeShareMemory(sharedMemory, 4096);
return 0;
}MemoryContext
除了共享内存之外,其他进程独享的内存空间是通过MemoryContext进行分配的。
PostgreSQL的MemoryContext机制实现,本质上是对malloc,free,realloc的封装。但是glibc的malloc为了多线程架构的实现,加入了一些锁来保证并发的一致性,而PostgreSQL本身是多进程单线程的架构,所以完全使用glibc的内存接口,性能是有损耗的。
另外,MemoryContext的封装也可以避免在使用过程中的内存泄漏问题。
这一块的详细内容可以看知乎专栏:图解PostgreSQL--MemoryContext(1),整体相对复杂,我也没还没看完。
初始化LWLocks
LWLock结构初始化的入口位于CreateLWLocks,其中分配的锁分为两部分:
-
NUM_FIXED_LWLOCKS: pg内部使用到的锁 -
Named LWLock: 这部分锁是给插件使用的,需要在
_PG_init内执行RequestNamedLWLockTranche进行注册才会给它分配空间,每个named tranche都需要指定包含锁的数量以及锁的名字
对于固定锁来说,其中又分为4部分,总计208把:
-
Individual locks: 通过
lwlocknames.txt得到,NUM_INDIVIDUAL_LWLOCKS就是锁的数量,pg14中默认有48把 -
buffer partition lock: 默认为128把
-
lock manager lock: 默认为16把
-
predicate lock manager lock: 默认为16把
空间分配
首先我们需要为所有的锁分配空间,空间计算的代码位于LWLockShmemSize内
-
首先我们需要一个int来统计当前NamedTranches的数量,即
LWLockCounter -
对于存放锁的
MainLWLockArray来说,需要的空间就是LWLockPadded乘以锁的总数量 -
之后为每个named tranche分配空间,即
NamedLWLockTranche结构体,存储了tranchID和tranchName -
最后我们还需要一段空间来存放每个tranche名字的字符串表示,
tranchName就会指向这里,通过tranchID就能找到每个tranche的名字
在分配时,分配大小会额外加上LWLOCK_PADDED_SIZE=128,这是为了保证我们可以为MainLWLockArray分配一个cache line对齐的地址,同时将LWLockCounter置于MainLWLockArray之前
LWLockCounter = (int *) ((char *) MainLWLockArray - sizeof(int));锁的初始化
初始化过程分为两步:初始化固定锁、初始化动态锁。具体初始化过程就是依次对每个锁调用LWLockInitialize进行初始化,初始化时需要传入每个锁对应的ID,该ID用于反向查找锁的名字。
- 对于固定锁来说
- Individual locks的锁ID各不相同,其对应的名字保存在
IndividualLWLockNames中 - 固定锁中的其他三个部分分别使用一个锁ID和锁名,保存在了
BuiltinTrancheNames中
- Individual locks的锁ID各不相同,其对应的名字保存在
/* Initialize all individual LWLocks in main array */
for (id = 0, lock = MainLWLockArray; id < NUM_INDIVIDUAL_LWLOCKS; id++, lock++)
LWLockInitialize(&lock->lock, id);
/* Initialize buffer mapping LWLocks in main array */
lock = MainLWLockArray + BUFFER_MAPPING_LWLOCK_OFFSET;
for (id = 0; id < NUM_BUFFER_PARTITIONS; id++, lock++)
LWLockInitialize(&lock->lock, LWTRANCHE_BUFFER_MAPPING);
/* Initialize lmgrs' LWLocks in main array */
lock = MainLWLockArray + LOCK_MANAGER_LWLOCK_OFFSET;
for (id = 0; id < NUM_LOCK_PARTITIONS; id++, lock++)
LWLockInitialize(&lock->lock, LWTRANCHE_LOCK_MANAGER);
/* Initialize predicate lmgrs' LWLocks in main array */
lock = MainLWLockArray + PREDICATELOCK_MANAGER_LWLOCK_OFFSET;
for (id = 0; id < NUM_PREDICATELOCK_PARTITIONS; id++, lock++)
LWLockInitialize(&lock->lock, LWTRANCHE_PREDICATE_LOCK_MANAGER);- 对于动态锁,使用
LWLockNewTrancheId得到ID进行初始化,每组锁共用一个IDLWLockNewTrancheId就是使用共享内存中的LWLockCounter自增得到新的IDIndividualLWLockNames中有48个名字,BuiltinTrancheNames中有24个名字,所以LWLockCounter的初始值就是72
最后初始化NamedLWLockTrancheArray以及trancheNames,保存锁名并记录动态锁ID到动态锁名的映射
使用72以内的ID查询,会从IndividualLWLockNames和BuiltinTrancheNames两个数组内直接返回字符串。使用72以上的ID查询,返回LWLockTrancheNames对应的动态锁名(查询的函数为GetLWTrancheName)
如何添加新的锁
最简单的方法就是修改lwlocknames.txt,然后就可以直接使用了。
当然上面的方法比较适合于添加单把锁,如果我们要添加一组功能相同的锁的话,这样就不是太方便了。
这时候就可以选择在InitializeLWLocks内添加所需要的锁
-
首先需要在
BuiltinTrancheIds内添加一个新的组,在BuiltinTrancheNames也对应地加上锁名。(注意修改时下标要对应,并且保证LWTRANCHE_FIRST_USER_DEFINED是最后一个元素,其用来确定数组内元素数量) -
之后需要修改
NUM_FIXED_LWLOCKS,加上对应锁的数量 -
最后在
InitializeLWLocks内初始化每个锁,初始化过程可以参考原始的代码,建议放在固定锁的最后一部分进行初始化,以最小化改动
当然,这也不是唯一的方法,可以注意到BuiltinTrancheNames有24个名字,但是初始化中只使用到了3个,那么其余的都用在哪里了呢?以LWTRANCHE_WAL_INSERT为例,可以找到其出现在XLOGShmemInit函数内,这里使用了ShmemInitStruct分配空间然后自行进行了初始化
XLogCtl = (XLogCtlData *)
ShmemInitStruct("XLOG Ctl", XLOGShmemSize(), &foundXLog);
...
allocptr = ((char *) XLogCtl) + sizeof(XLogCtlData);
allocptr += sizeof(XLogRecPtr) * XLOGbuffers;
allocptr += sizeof(WALInsertLockPadded) - ((uintptr_t) allocptr) % sizeof(WALInsertLockPadded);
WALInsertLocks = XLogCtl->Insert.WALInsertLocks = (WALInsertLockPadded *) allocptr;
for (i = 0; i < NUM_XLOGINSERT_LOCKS; i++)
{
LWLockInitialize(&WALInsertLocks[i].l.lock, LWTRANCHE_WAL_INSERT);
WALInsertLocks[i].l.insertingAt = InvalidXLogRecPtr;
WALInsertLocks[i].l.lastImportantAt = InvalidXLogRecPtr;
} 又比如BufferDesc内的content_lock,也是通过同样的方法在InitBufferPool内进行初始化的。这种方式适合于需要将锁和某些数据结构绑定使用的场景里。